
Publications
Entropy-Guided Sequence Weighting for Efficient Exploration in RL-Based LLM Fine-Tuning
Preprint, 2025
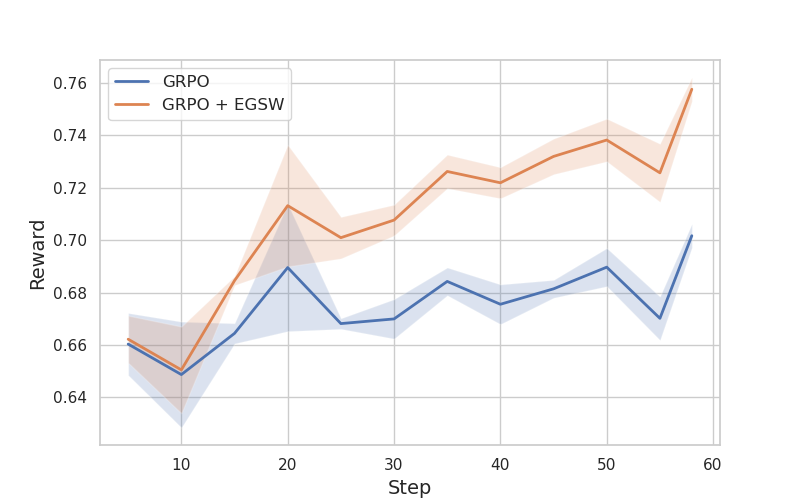
RL-based fine-tuning approaches emerged as effective approach for improving reasoning capabilities of the LLMs. However, fine-tuning LLMs with RL presents significant challenges, particularly in high-dimensional state spaces where efficient exploration is crucial. Exploration methods such as Monte-Carlo Search Tree (MCTS) have been highly successful in games (AlphaZero) and inference-time search (Chatgpt-o1). But, computation cost of MCTS makes it impratical for LLM fine-tuning. To overcome these challenges, we introduce Entropy-Guided Sequence Weighting, a method that improves exploration efficiency in RL-based LLM fine-tuning while maintaining computational feasibility. Our method dynamically balances exploration and exploitation by assigning adaptive weights to generated sequences based on their entropy and advantage values.
IQ-Flow: Mechanism Design for Inducing Cooperative Behavior to Self-Interested Agents in Sequential Social Dilemmas
Published in In Proc. of the 22nd International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2023
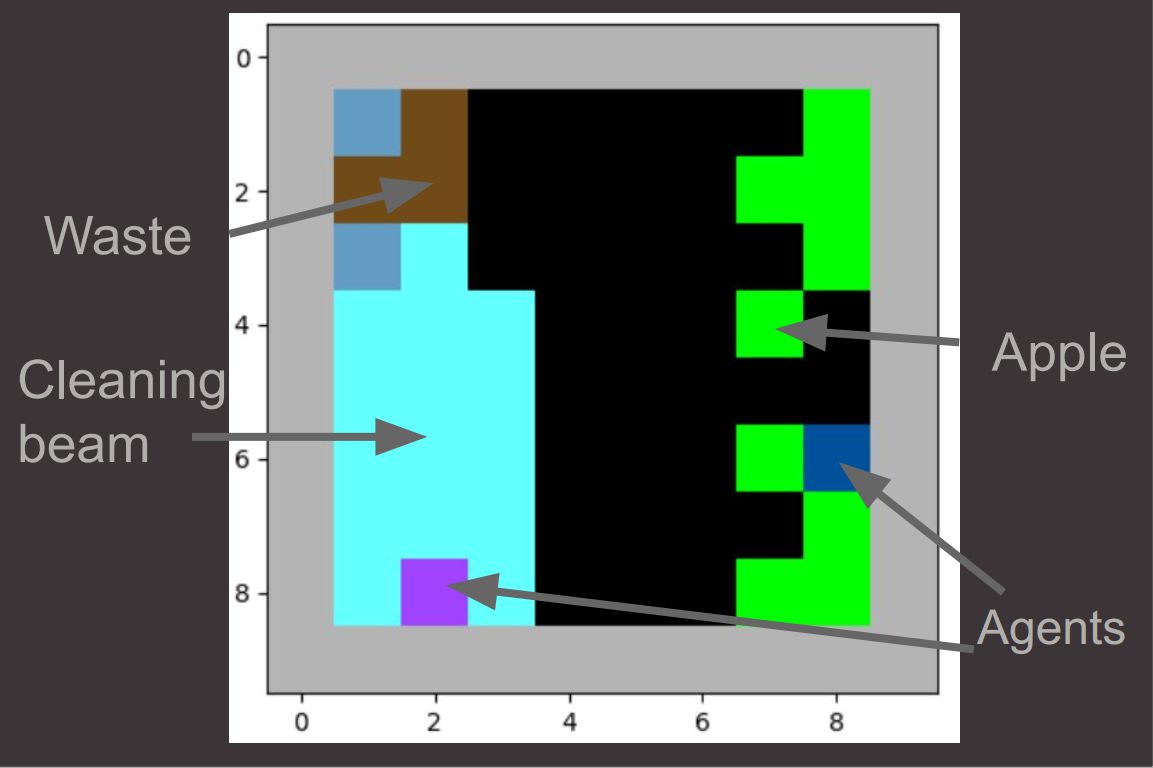
Self-interested agents often fail to reach the cooperative objectives in MARL environments. In this paper, we propose an incentive mechanism that alters the reward structure of the agents. Unlike previous approaches, our method does not rely on assuming the agent’s internal parameters or learning strategies. Instead, IQ-Flow leverages meta-gradient learning and offline reinforcement learning to ensure that both cooperative policies and agent self-interested policies yield identical actions. In another sense, our algorithm eliminates the social dilemma in the environment by providing incentives that encourage agents to behave cooperatively.
Empirical Robustness Analysis of Learning to Incentivize Other Self-Interested Agents
Published in in Proceedings of the Conference of Computational Science and Computational Intelligence (CSCI), 2022
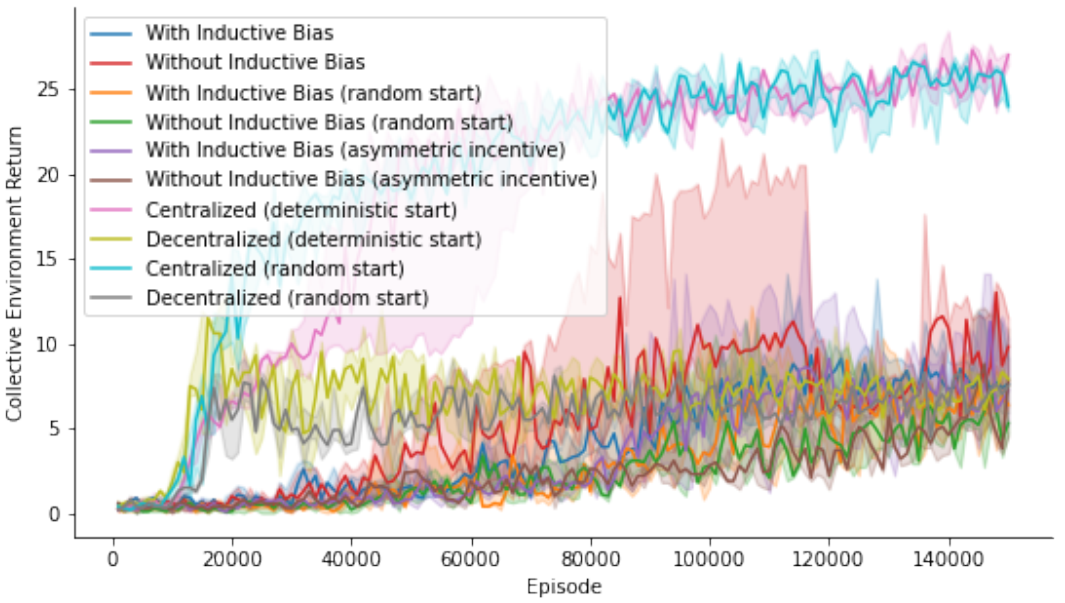
One of the most effective ways to solve social dilemma problems in multi-agent settings is to develop learning-based approaches that modify the reward function. Among these approaches, Learning the Incentivize Others (LIO) enables independent self-interested agents to incentivize each other by an additive incentive reward and demonstrates the method’s success in several sequential social dilemma environments. We investigate LIO’s performance under a variety of different setups in public goods game Cleanup in order to analyse its robustness against necessity of including inductive bias in incentive function, randomness in initial agent position with an option of asymmetric incentive potential, and assess its stability under frozen incentive functions after agents’ explorations are reset.